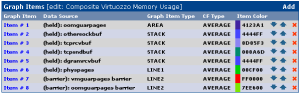
GoDaddy (Virtuozzo) Virtual Server in cacti
A business site I provide some support to runs on a GoDaddy virtual Linux server. We were having some performance issues so I dug into
A business site I provide some support to runs on a GoDaddy virtual Linux server. We were having some performance issues so I dug into
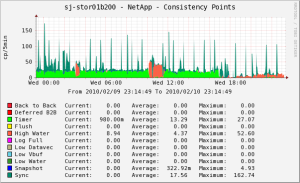
Recently went on a couple of training courses on NetApp fundamentals and performance. The tutors both recommended that every good NetApp admin should spend a